【2.0】C-数据类型及运算
【2.0】数据类型及运算
前言
c 语言经典的入门内容,笔记断断续续写了一个多礼拜,最近一直在考试,碰到考试周了就很头疼。
标识符和关键字
C程序由C语言的基本字符组成,基本字符依据规则组成C语言的标识符和关键词,再按照语法要求构成程序。
标识符
C语言中由用户命名的符号称为标识符,用来标明用户设定的变量名,数组名,函数名,结构体名等。标识符必须由有效字符构成,也就是标识符要合法。
C语言的命名规则如下:
标识符只能由字母,下划线,数字组成,且第一个字符必须是字母或者下划线,不能是数字。如:
cla,cla1都是合法的,但是2cla,%123等都是不合法的。字母区分大小写,例如:
AB和ab是两个不同的标识符当然有的计算机语言不区分大小写;例如:VB语言不区分大小写
不能使用C语言中的关键字
C语言虽然本身不限制标识符的长度,但是实际长度收到不同的编译系统和机器系统的限制。
为了提高标识符的可读性,一般来说,业内较为流行的有驼峰命名法,下划线命名法和匈牙利命名法
- 驼峰命名法
小驼峰命名法:除了第一个单词之外,其他单词首字母都大学。例如:
myFileName,openFileSys等。常用于变量名,函数名;
大驼峰命名法(又称帕斯卡命名法):所有单词的首字母均大写,例如:
OpenFileSys,ConDataBase等常用于类名,属性,命名空间等;
- 下划线命名法
- 名称中的每一个逻辑断点都用一个下划线来标记,例如,函数名
print_student_name。下划线命名法是随着C语言的出现而流行的,在UNIX/Linux这样的环境,以及GNU代码中非常普遍。
- 名称中的每一个逻辑断点都用一个下划线来标记,例如,函数名
- 匈牙利命名法
- 该命名法由微软公司名为 Charles Simonyi 的匈牙利程序员发明的,其基本原则是,变量名=属性+类型+对象描述。通过在变量名前面加上相应的小写字母的符号标识作为前缀,标识出变量的作用域,类型等。这些符号可以多个同时使用,顺序是先
m_(成员变量),再指针,再简单数据类型,再其他。例如,m_lpsStr表示指向一个字符串的长指针成员变量。
- 该命名法由微软公司名为 Charles Simonyi 的匈牙利程序员发明的,其基本原则是,变量名=属性+类型+对象描述。通过在变量名前面加上相应的小写字母的符号标识作为前缀,标识出变量的作用域,类型等。这些符号可以多个同时使用,顺序是先
关键字
C语言规定具有特别意义的字符串为关键字(即保留字),关键字不能作为用户标识符。在一些IDE中,关键字会显示为彩色字符来做明显标识。
C语言的关键字如下表,可以分为以下几类:
- 类型声明符。如表示整型的
int等 - 语句定义符。用于表示语句功能的,例如条件语句的
if,else等 - 预处理命令字。它们是以固定的形式用于专门的位置,表示一个预处理命名,通常将它们当作关键字来看待,如文件包含预处理命令
include等
C语言中的关键字
| int | long | short | float | double | char |
|---|---|---|---|---|---|
| while | do | switch | case | continue | break |
| const | signed | unsigned | if | else | for |
| default | auto | register | static | extern | void |
| return | struct | union | enum | typedef | volatile |
| goto | sizeof | inline | restrict | bool | _ Complex |
| _Imaginary | include | define | undef | ifdef | ifndef |
| endif |
其中的bool,_Complex和_Imaginary是C99新增的关键字,其余的关键字全由小写字母组成。
常量与变量
C程序的处理对象为数据,它们通常以常量或者变量的形式出现。常量是在程序运行过程中值保持不变的量,变量则是在程序运行过程中值可以改变的量。
常量
C语言的常量有两种,一种是字面常量,字面常量不需要定义,是非定义量,即通常的数字和字符,例如:123,456,-123,12.4或者字符”A”,”b”等。第二种是自定义常量,或者符号常量,以一个标识符来代表某一个字面常量,通常利用C语言的宏定义命令 define 来定义,代码示例:
1 |
其含义为以标识符 PI 来代表数据 3.1415926。宏定义命令之后,程序凡是用到 3.1415926 的地方都可以使用 PI 来表示,减少书写的工作量,还可以通过别名来提高程序的可读性。
使用符号常量后,程序的可维护性好,当需要修改某一常量时,只要修改宏定义中的常量即可,不必逐一修改。
有关于宏的知识,后面会详细讲述
变量
每个变量都有三个属性:变量名,存储空间,变量值。
- 变量名:即变量的名字,是我们自定义的标识符,程序中通常使用变量名来对变量进行引用。
- 存储空间:每个变量在内存中都占用一定的存储单元。存储单元的大小由变量的类型决定。在C程序中,变量可以通过变量名称访问,也可以通过变量的地址来访问。
- 变量值,即变量存储空间中存放的值。
在C程序中,对任何变量都必须 先声明,后使用 ,只有在定义了变量的名字,数据类型之后,才能对变量进行各种运算。
数据类型
完整的变量定义语句包含两个元素:变量名和数据类型。数据类型规定了变量的三个限制:
- 变量所占用的存储空间的大小,存储空间以字节为单位,如整型变量占用2个字节,浮点型占用4个字节。
- 变量的取值范围,变量的取值返回与存储空间的大小有关,如整型取值范围为 $-32728$~$32767$ ,浮点型取值范围为 $-3.4 \times 10^{-38}$ ~ $3.4 \times 10^{38}$ 。
- 变量能进行的运算。如只有整型或者字符型的数据可以进行”取余”运算
关于为什么整型的取值范围为 -32728~32767 ,详情参见 原码,反码,补码的前世今生
C语言的数据类型如下图所示:
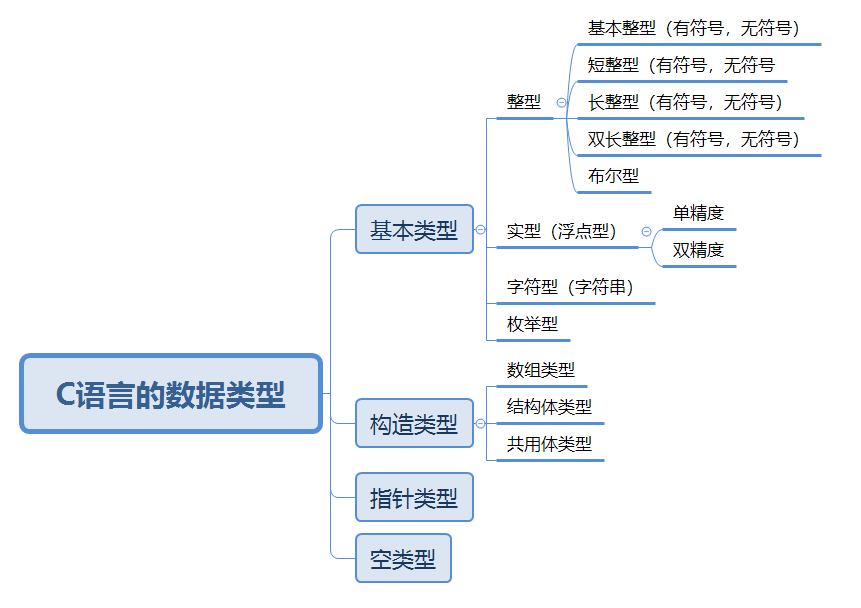
存储类型以字节为单位,实际长度由机器字长决定。整型数据取值范围与存储长度一致,但浮点型数据的取值范围还与其系统存储格式有关。
整型数据
整型数据包括整常数和存放整数的变量,C语言中整型常量可以有三种表示形式:
- 十进制形式,如15,-1555
- 八进制形式。C语言中八进制以数字 0 开头,只能以 0~ 7 这8个数字组合表示,如 0271 对应十进制的数为 $2 \times 8^2 + 7 \times 8^1 +1 \times 8^0 = 185$
- 十六进制形式。C语言中十六进制数以 0x 或者 0X 开头,可以用 0
9 这10个数表示以及字母 AF(或 a~f )组合来表示。如 0x61F 对应的十进制数为 $6 \times 16^2 + 1 \times 16^1 + 15 \times 16^0 = 1567$
整型数据按存储空间长度可以分为五种:
基本整型:关键字为
int。在16位计算机中基本整型数据占据2个字节,最高位表示正负符号位,取值范围 $-32768$ ~ $32767$。在32位计算机中基本整型占据4个字节,最高位位正负符号位,取值范围为 $-2147493648$ ~ $2147483647$ 。代码示例:1
int a; //声明了整型变量 a
**短整型:关键字为
short int(int可以省略)**。短整型占2个字节,最高位为符号位,取值范围为 $-32768$ ~ $32767$。代码示例:1
2short int a; //声明了短整型变量 a
short a;**长整型:关键字为
long int(int可以省略)**。长整型占4个字节,最高位为符号位,取值范围为 $-2^{31}$ ~ $2^{31}-1$ 。代码示例:1
2long int a; //声明了长整型变量 a
long a;双长整型:关键字为
long long int(int可以省略)。双长整型占 8 个字节,最高位为符号位,取值范围为 $-2^{63}$ ~ $2^{63}-1$ 。代码示例:1
2long long int a; //声明了双长整型变量 a
long long a;布尔型:关键字为
bool。布尔型数据占据 2 个字节。其取值有两种:真(TRUE/1)和假(FLASE/0)。代码示例:1
_Bool x; //声明了布尔型变量 x
C99之后的Bool被定义为
_bool,再次之前布尔类型是通过int类型来定义的
以上基本整型,短整型,长整型及双长整型都是可正可负的,可以看作省略了关键字 signed 的有符号类型,即以上的定义可以写成:
1 | signed int a; |
如果在使用的数值无须符号,则定义为无符号类型,其关键字为 unsigned 。 定义无符号类型的整型变量只需要在前面加上该关键字即可。代码示例:
1 | unsigned int a; |
无符号类型即全为正数,无负数(抛弃了符号位)
无符号关键字只适用于整型变量。
C语言的变量必须“先定义,后使用”,从上面的示例可以看出,C语言中变量的定义格式如下:
1 | 存储类型 数学类型 变量名称; |
其中存储类型可以默认省略。
实型数据
实型数据包括实型常数(常量)和实型变量,实型数据即带小数的数据(实数),或称浮点数。
C语言中实型常量只用十进制形式,但是其表示方式有两种:
- 直接十进制形式,如:0123,-456.48。
- 指数形式,如: $1.23e-2$,$-4.123e2$。
指数形式通常用来表示一些比较大的数值,格式为:实数部分+字母 E 或者 e +正负号+整数部分。其中的 E 或者 e 表示十次方,即 $实数e^{-/+整数}$,并不是常规数学表达式中的自然底数,正负号表示指数部分的符号,整数为幂的大小。字母 E 或者 e 之前必须有数字,之后的数字必须为整数。
C语言中实型数据按长度大小可以分为三类:
- **单精度型:关键字为
float**,占 4 个字节。提高 7 位有效数字,取值范围为 $-3.4 \times 10^{-38}$ ~ $3.4 \times 10^{38}$。 - **双精度型:关键字为
double**,占 8 个字节,提供 16 位有效数字,取值范围为 $-1.7 \times 10^{-308}$ ~ $1.7 \times 10^{308}$。 - **长双精度型:关键字为
long double**,占 16 个字节,取值范围为 $-1.2 \times 10^{-4932}$ ~ $1.2 \times 10^{4932}$。
计算机中实型数据实际上是以指数的形式存储的,用二进制来表示小数部分以及用 2 的幂次来表示指数部分。但不同长度类型中究竟用多少位来表示小数部分,多少位来表示指数部分,各种 C 编译系统不尽相同。
【实例】输出单精度实数,验证有效数字位数
【代码示例】
1 | float a = 1111111.222222; //小数点前7位 |
【输出结果】 
【说明】我用的是VScode,手动配置链接的 MinGW,可以得出此编译器的单精度浮点的有效位为 8 位。
【实例】输出双精度实数
【代码示例】
1 | double a = 1111111.22222; |
【输出结果】 
【说明】
- 使用
%f可以输出单精度或者双精度浮点数,对于长双精度浮点数,使用%Lf。 double输出的时候,默认输出小数后 6 位 ,不足 6 位时补 0,多余 6 位时四舍五入后只输出前 6 位。- 可以使用
%.xf修改 x 的值来指定输出小数点后几位
字符型数据
C语言中字符型数据包括字符常量和字符变量。
字符常量必须用单引号括起来,单引号中只能为单个字符,在内存中占用一个字节,例如:A,a,#等。
字符型数据在C语言中是以 ASCII 码形式存储的,即字符常量的数值就是其保持的 ASCII 码的值,如:A 的 ASCII 码值为 65 。因为 ASCII 码值为整型,故C语言中字符型数据与整型数据可以在同一个表达式中出现,并且不会进行类型转换。例如: a-32相当于 97-32 。
可以通过对大写字母 +32 来进行大小写转换。
C语言中还有一类特殊的字符,称为转义字符,以 \ 开头,根据斜杠后面的不同字符表达特定的含义。常用的转义字符如下:
\n:回车换行。\b:退格\r:回车\t:水平制表,即横向跳到下一个制表位。\v:垂直制表,即纵向跳到下一个制表位。\\:反斜线符号\。- **
\':单引号'**。 - **
\":双引号"**。 \a:鸣铃。\f:走纸换页。\ddd:1~3位八进制数所代表的字符。\xhh:1~2位十六进制数所代表的字符
实际上,利用 \ddd 和 \xhh 可以表示任意一个字符,分别利用八进制和十六进制转换为 ASCII 码的值。例如:\123 输出表示为 S。
**定义字符型变量的关键字为 char**,字符型变量在内存中占用一个字节。需要注意的是,在使用字符型存储整型时,只有一个字节的大小,注意溢出问题。
【实例】输出字符及其对应的 ASCII 码
【代码示例】
1 | char ch = 'a'; |
【输出结果】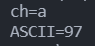
此外,C语言中还有一类数据,是用一对双引号括起来的一个或者多个字符,称为字符串常量,简称字符串,例如 Hello,World。
但是C语言并没有字符串类型,字符串类型的处理需要字符型数组。数组的内容后面会涉及,此处先不赘述。
数据类型的转换
C语言允许不同类型的数据混合运算,运算中可以按照一定的规则或者人为干预进行类型转换。转换的方式分为两种:隐式类型转换和显式类型转换。
隐式类型转换
隐式类型转换是编译系统自动进行的,不需要人为干预,隐式类型转换遵循三个基本规则:
如果参与运算的变量类型不同,则先转换成同一类型,然后进行运算。
按“低位向高级转换”原则,如果运算中有几种不同类型的操作数,则同一转换为类型高的数据类型,再进行运算,例如:
1
2
3
4int a = 2;
float b = 2.1;
double c = 2.3;
printf("%f",a + b + c);在计算的时候,先将 a,b转换为
double类型,然后进行计算,所得的结果为double类型。各种类型转换方向如下图所示:
1
2
3graph LR
A(char,short) -->B(int) -->C(unsigned) -->D(long) -->E(double)
F(float) -->E(double)浮点型运算时系统一律转换为双精度浮点进行运算,运算结束后再根据类型来转换回去,以防止计算精度丢失。
赋值运算符号作业两边的数据类型不同时,赋值号右边数据类型将转化为与左边数据一致的类型。例如:
1
2
3
4
5int a = 2;
float b = 2.1;
double c = 2.3;
int d = a + b + c;
printf("%d",d);a+b+c得出的结果为
double类型,在进行赋值后,被强制转换为 d 的int类型,丢失部分精度。
强制类型转换
强制类型转换即显式类型转换,其作用是人为将相关类型转换为指定的数据类型。转换格式代码示例:
1 | (目标的类型标识符)(要转换的变量) |
【实例】使用强制类型转换参与运算
【代码示例】
1 | int a = 2; |
【输出结果】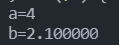
【说明】强制类型转换不改变原数据类型,只是在参与运算的时候改变运算时的参与数据类型。
运算符和表达式
运算表达式是对数据进行操作和处理的基本单位,一个运算表达式由两m个要素组成的运算量与运算符。运算量包括常量和变量。C语言提供了很多基本运算来实现运算处理,这些运算符可以分为以下几类:
- 算术运算符:
+,-,*,/,%(求余数,或者称模运算)。 - 自增自减运算符:
++,--。 - 关系运算符:用于比较运算,包括
>,<,>=,=<,==,!=(不相等)。 - 逻辑运算符:用于逻辑运算,包括
&&(与),||(或),!(非)。 - 位运算符:按照二进制位进行运算,包括
&(位与),|(位或),~(位非),<<(左移),>>(右移)。 - 条件运算符:
?:条件运算符是C语言中唯一一个三目运算符,用于条件求值。 - 赋值运算符:可以分为下面三类
- 简单赋值运算符:
= - 复合算术赋值运算符:
+=,-=,*=,/=,%=。 - 复合位位运算赋值运算符:
&=,|=,^=,>>=,<<=。
- 简单赋值运算符:
- 逗号运算符:
,。 - 指针运算符:
*。 - 地址运算符:
&。 - 构造类型特殊运算符:
.(引用成员运算符),->(指向成员运算符),[](下标运算符)。 - 小括号运算符:
()。 - 花括号运算符:
{}。 - 长度运算符:
sizeof(类型运算符)用于计算数据类型所占的字节数。 - 类型转换运算符:(类型标识符)(表达式)
算术运算符和算术表达式
算符运算符及其相关
算术运算符:+,-,*,/,%(求余数,或者称模运算)。
需要注意的是:
- 关于除法运算符
/:如果两个整数相除,则结果为整数,小数部分将被去掉,例如:5/2,结果为 2,而不是 2.5。两个操作数只要有一个是浮点数,则结果为浮点数。 - 关于模运算符
%:只适用于两个整数取余,其两个运算量只能是整型或者字符型,不能是其他类型,取余结果的符号是由被除数决定的,例如:7%(-3)的结果是 1,而(-7)%(-3)结果为 -1。
算术运算符的优先级与结合性
算术表达式的计算按运算符的优先级从高到低依次进行。双目运算符的优先级与基本四则运算法则一致,先乘除再加减。
在一个运算符出现同级运算符时,运算遵循“左结合律”,即按照自左向右进行计算,例如:a+b+c,先 a+b ,再 +c。
赋值运算符和赋值表达式
赋值运算符及其说明
赋值运算符的作用时将一个数据赋值给一个变量。赋值运算符:可以分为下面三类
- 简单赋值运算符:
= - 复合算术赋值运算符:
+=,-=,*=,/=,%=。 - 复合位位运算赋值运算符:
&=,|=,^=,>>=,<<=。
例如:
a+=1等价于a=a+1,其余同理,此处不做过多说明。
所有赋值运算符都是将右边的值赋值给左边,因此赋值运算符左边只能为变量。
赋值运算符的结合性
赋值运算符遵循“右结合性”,方向为“自右向左”。
【实例】验证赋值运算符的结合性
【代码示例】
1 | int a =10; |
【输出结果】 
自增自减运算符
自增自减运算符及其表达式
自增运算符 ++,自减运算符 -- 的作用是让变量加 1 或者减 1 ,常用于循环结构中,但自增自减运算符都有前置和后置之分,前置后置决定了变量使用与计算的顺序:
- 自增运算符前置:如
++i,是先将 i 的值加 1 后,再使用 i 的值。 - 自增运算符后置:如
i++,是先使用 i 的值,然后再加 1 。 - 自减运算符前置:如
--i,是先将 i 的值减 1 后,再使用 i 的值。 - 自减运算符后置:如
i--,是先使用 i 的值,再使 i 的值减 1 。
自增自减运算符只能作用域变量,不能用于常量或者表达式,如 3++,--(x*y)等都是不合法的。
自增自减的结合性
自增自减运算符为右结合性,结合方向为“自右向左”。需要注意的是,自增自减运算符不可以作用于表达式。
【实例】验证自增自减运算符结合性
【代码示例】
1 | int a, b,c; |
【输出结果】 
【说明】 !xx代表数值,结果为 0 。!默认非 0 值为真,采用非操作后,变为假,然后整型输出就是 0 。反之,如果 !0,则输出 1 。
逗号运算符和逗号表达式
C语言中,,逗号运算符作为分割符号。代码示例:
1 | int a,b,c; |
也可以作为运算符,用于链接多个表达式,代码示例:
1 | 表达式 1,表达式 2,...,表达式 n; |
当逗号用于运算时,将从左到右依次求取各个表达式的值。
数据的输入和输出
在C语言中通过输入/输出函数实现数据的输入/输出。系统提供了一批标准输出函数,这些函数包含在一些头文件中,称为库函数。要使用这些函数,必须在程序开头事先用文件包含命令 #include 包含这些头函数。
以下部分,主要是标准输入/输出函数,即 <stdio.h> 库函数里的内容。
格式输入函数 scanf
格式输入函数 scanf 将数据按规定的格式从键盘上读取到指定变量中。代码示例:
1 | //格式示例 |
利用 scanf 函数从键盘读入数据时,需要注意以下几点:
输入多个数据时,建议使用空格或者相关分隔符进行分割,这样数据的输入不会出现二义性。代码示例
1
2
3//比如说下面这样
int a,b,c;
scanf("%d %d %d", &a,&b,&c);输入的数据个数与顺序要与
sacnf()函数一致。如果格式控制字符串中有普通字符,则必须依次原样输入,否则可能发生错误。代码示例:
1
2
3
4
5
6int a,b,c;
scanf("a=%d,b=%d,c=%d", &a,&b,&c);
printf("%d,%d,%d", a, b, c);
//输入的时候需要输入
//a=1,b=2,c=3
下面对C语言的格式符进行解释说明。
格式符皆以 % 开始标记,格式示例:
1 | % [m][l或h]数据类型声明字母 |
其中,方括号为可选项,可以为空,但是数据类型字母声明不可缺省。
- 数据类型声明字母
- d:输入十进制整数。
- o:输入八进制整数。
- x:输入十六进制整数。
- u:输入无符号十进制整数。
- f:输入小数形式实型数。
- e:输入指数形式实型数。
- c:输入单个字符。
- s:输入字符串。
l和h为长度格式符。l用于规定长整型和双长整型,h则规定输入为短整型。%ld,%lo,%lx:表示输入数据为长整型十进制,长整型八进制,长整型十六进制。%lf,le:表示输入双精度型小数形式,双精度指数形式。%hd,%ho,%hx:表示输入的数据类型为短整型十进制,短整型八进制,短整型十六进制。
m为十进制整数,用于指定输入数据的宽度(即数字个数)。代码示例:输入 123456,输出结果:1
2
3int a;
scanf("%5d", &a);
printf("%d", a);
该代码读取的时候只读取前 5 个字符,即5个宽度。后面的默认去除。
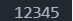
对于指定了宽度的输入格式,数据之间可以无分隔符,系统会自动截取宽度来读入。代码示例:
1 | int a,b; |
输入1234567,输出结果: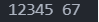
对于浮点型,数据宽度为数据的整体宽度,包括小数点在内,即数据宽度 m=整体位数+1(小数点)+小数位数。格式输入函数只能指定数据整体的宽度,无法指定小数位数,这和后面输出函数 printf时不同的。代码示例:
1 | float a,b; |
输入 1.23.4 ,输出结果:
格式输出函数 printf
格式输出函数 printf 将指定的数据按指定的格式输出到控制台上,代码示例:
1 | //学术定义版 |
printf() 函数中的格式控制字符和 scansf() 函数一致,包含格式符与普通字符。格式符用于控制输出格式,普通字符将原样输出显示。代码示例:
1 | float a=1.2,b=1.3; |
其中 %f 为格式控制符, a= 则是普通字符,会输出到屏幕上。printf() 中的格式符与 scanf() 一致,皆以 % 为开始标记,但是相比要复杂一些,格式如下:
1 | % [±] [0] [m] [.n] [l或h] 数据类型字母 |
数据类型声明字母与
scanf()基本一致,有少许扩充:- d:以十进制整数形式输出。
- o:以八进制整数形式输出。
- x或者X:以十六进制整数形式输出。
- u:以无符号十进制整数形式输出。
- f:以小数形式实型数输出。
- e或者E:以指数形式实数输出。
- c:以单个字符形式输出。
- s:以字符串形式输出。
- g或者G:由系统决定采用
%f格式还是%e格式,以使输出宽度最小,不输出无意义的 0。 - % :输出百分号(例如
%%)
l或h的含义同sancf();l双精度/长整型,h短整型。m.n指定输出数据的宽度。
输出整数时:只有m,没有.n部分。m表示输出整数的位数。如果整数的实际位数大于指定的m,则按照实际的位数输出,如果整数的实际位数小于指定m,则左边按位补空格。
输出浮点数时:m指定数据总宽度,含义与scanf函数相同, m=整数位数+1(小数位)+小数位数。**n指定小数位数**。
【实例】指定浮点数输出格式1
2float a=1.123,b=112.3;
printf("a=%3.1f b=%f", a, b);输出结果:
说明:
%3.1f指定了3位输出位数,排除一位小数点,.1指定了一位小数,则输出1.1。[0]指定输出数据空位置的填充方式,指定0则以0填充,不指定则默认空格填充。代码示例:
1
2
3int b = 123;
float a=1.123;
printf("a=%3.1f b=%05d", a, b);输出结果:
±指定输出数据的对齐方式:指定+时,输出右对齐;指定-时,输出左对齐;不指定时默认为+,输出右对齐。此项在不同的编译器有不同的处理方式,部分编译器不支持该格式

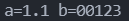
字符输出函数 getchar()
字符输入函数 getchar()的功能是从输入设备上读取输入的一个字符,其返回值即为所读入的字符,一般与赋值语句联用,将读取的字符传递给变量。代码示例:
1 | char c; |
该函数只会读取一个字符,如果输入多个字符,默认读取首字符。
字符输出函数 putchar()
字符输出函数 putchar()的功能是向控制台输出一个字符,调用格式如下:
1 | putchar(c); |
c可以是输出的字符常量或者变量,也可以是整型常量或者变量(此时系统会默认将其转化为ASCII码对应的字符)。代码示例:
1 | int a = 78; |
输出结果:
赋值语句和顺序结构程序设计
赋值语句
赋值语句即实现赋值功能,这里主要说明=运算符构成的赋值语句。代码示例:
1 | 变量=表达式; |
表达式可以是常量,变量或者运算式。关于=赋值要注意的是:
可以在声明变量的时候,直接赋值。代码示例:
1
int a = 1;
也可以先声明变量,后赋值,代码示例:
1
2int a;
a = 1;赋值语句可以嵌套,即表达式可以为赋值表达式,例如下面的操作是合法的,代码示例:
1
a = b = c = d = 1;
但是下面的操作是非法的,代码示例:
1
int a = b = c = d = 1;
顺序结构程序设计
C语言为结构化程序设计语言,分为三种基本结构:顺序结构,选择结构,循环结构。顺序结构是最基本的结构,程序从上到下依次执行。实际上选择结构与循环结构都为局部结构,是在整体顺序框架中的。顺序结构程序按照需要实现的功能逻辑顺序进行设计。
【实例】输入圆的半径,计算圆的面积
【代码示例】
1 |
|
【输出结果】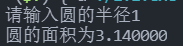
数学函数
数学函数属于库函数(Library function),在头文件math.h中,因此**要使用数学函数,必须在程序开头处使用文件包含命令#include将math.h包含进来,例如#include <math.h>**。C语言函数库提供了丰富的数学函数供用户使用,如下是一些常用的函数:
**绝对值函数
abs()**,代码示例:1
2
3
4//函数代码
int abs(int i);
//代码示例
abs(-5);输出结果:5
labs()以及fabs()分别用于求长整型数和实数的绝对值**开方函数
sqrt()**,代码示例:1
2
3
4//函数代码
double sqrt(double x);
//代码示例
sqrt(4);输出结果:2
**对数函数
log10()**(以10为底),代码示例:1
2
3
4//函数代码
double log10(double x);
//代码示例
log10(10);输出结果:1.000000
**自然对数函数
log()**,代码示例:1
2
3
4//函数代码
double log(double x);
//代码示例
log(2);输出结果:0.693147
**指数函数
exp()**(即$e^x$,以e为底),代码示例:1
2
3
4//函数代码
double exp(double x);
//代码示例
exp(2);输出结果:7.389056
**次方函数
pow10()**(即$10^x$,以10为底),代码示例:1
2
3
4//函数代码
double pow10(int p);
//代码示例
pow10(2);输出结果:100
部分编译器不支持该函数
**次方函数
pow()**(即$x^y$),代码示例:1
2
3
4//函数代码
double pow(double x,double y);
//代码示例
pow(2,2);输出结果:4
**正弦函数
sin()**,代码示例:1
2
3
4//函数代码
double sin(double x);
//代码示例
sin(30);输出结果:-0.988032
**余弦函数
cos()**,代码示例:1
2
3
4//函数代码
double cos(double x);
//代码示例
cos(30);输出结果:0.154251
**正切函数
tan()**,代码示例:1
2
3
4//函数代码
double tan(double x);
//代码示例
tan(30);输出结果:-6.405331
**反正弦函数
asin(),反余弦函数acos(),反正切函数atan()**,代码示例:1
2
3
4//函数代码
double asin(double x);
double acos(double x);
double atan(double x);
常见错误分析
- 遗漏符号,例如分号,逗号,引号等。
- 未定义就使用,或者在定义之前使用该变量。
- 使用中文字符不被识别。
- 语法错误。
- 数据溢出。




