大数据成矿预测系列(八) | 从定性到概率:逻辑回归——地质统计学派的“集大成者”
前言
这部分应该和证据权重法放在一起,建议先看证据权重法再看这个。
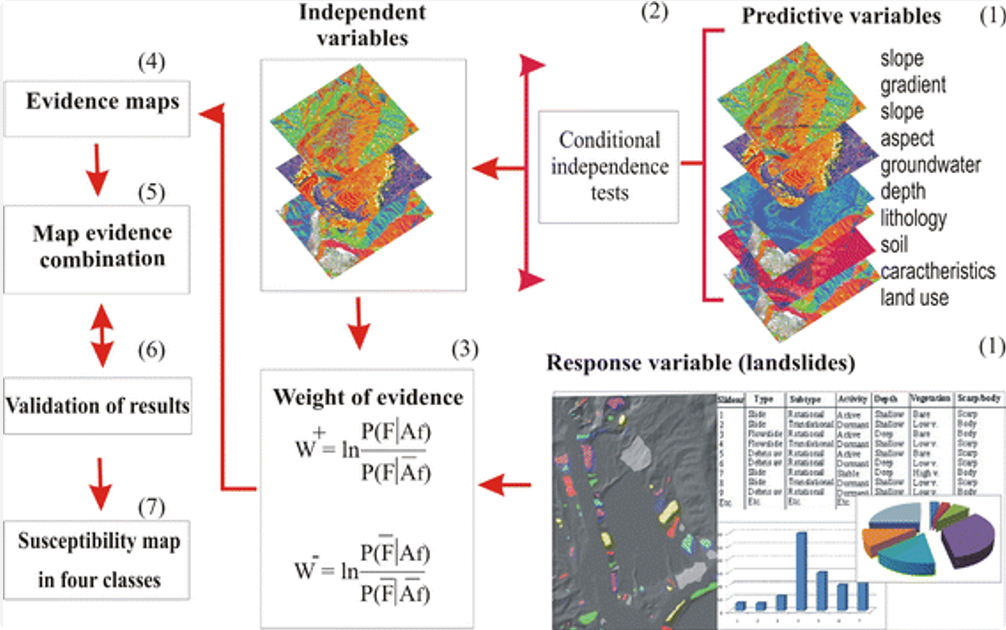
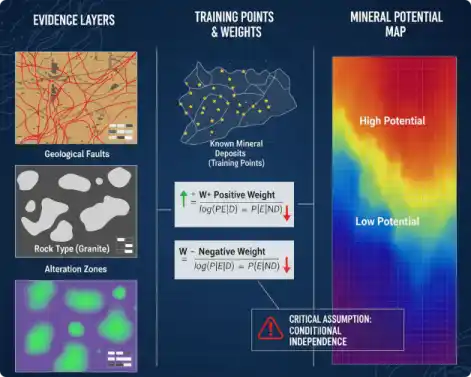
在众多早期的概率性方法中,证据权重法(Weights of Evidence, WofE)是应用最广泛、最被地质学家所接受的方法之一。WofE基于贝叶斯定理的对数线性形式,通过计算权重($W^+$ 和 $W^-$)来衡量每一个证据层(如“靠近断层”)与已知矿床点之间的空间关联强度。
然而,WofE方法的有效性建立在一个极其严苛且关键的统计假设之上:所有证据层相对于矿床的发生是“条件独立的”(Conditional Independence, CI)。在地质现实中,这一假设几乎总是被违背的。WofE的权重值提供了这样一种直观的度量,使其易于被非统计学专家所接受。这在地质直觉和统计严谨性之间造成了一种长期的紧张关系。
逻辑回归(Logistic Regression, LR)的出现,正是为了解决WofE模型中“条件独立性”假设这一核心科学难题。

逻辑回归的兴起:针对相关性证据的稳健解决方案
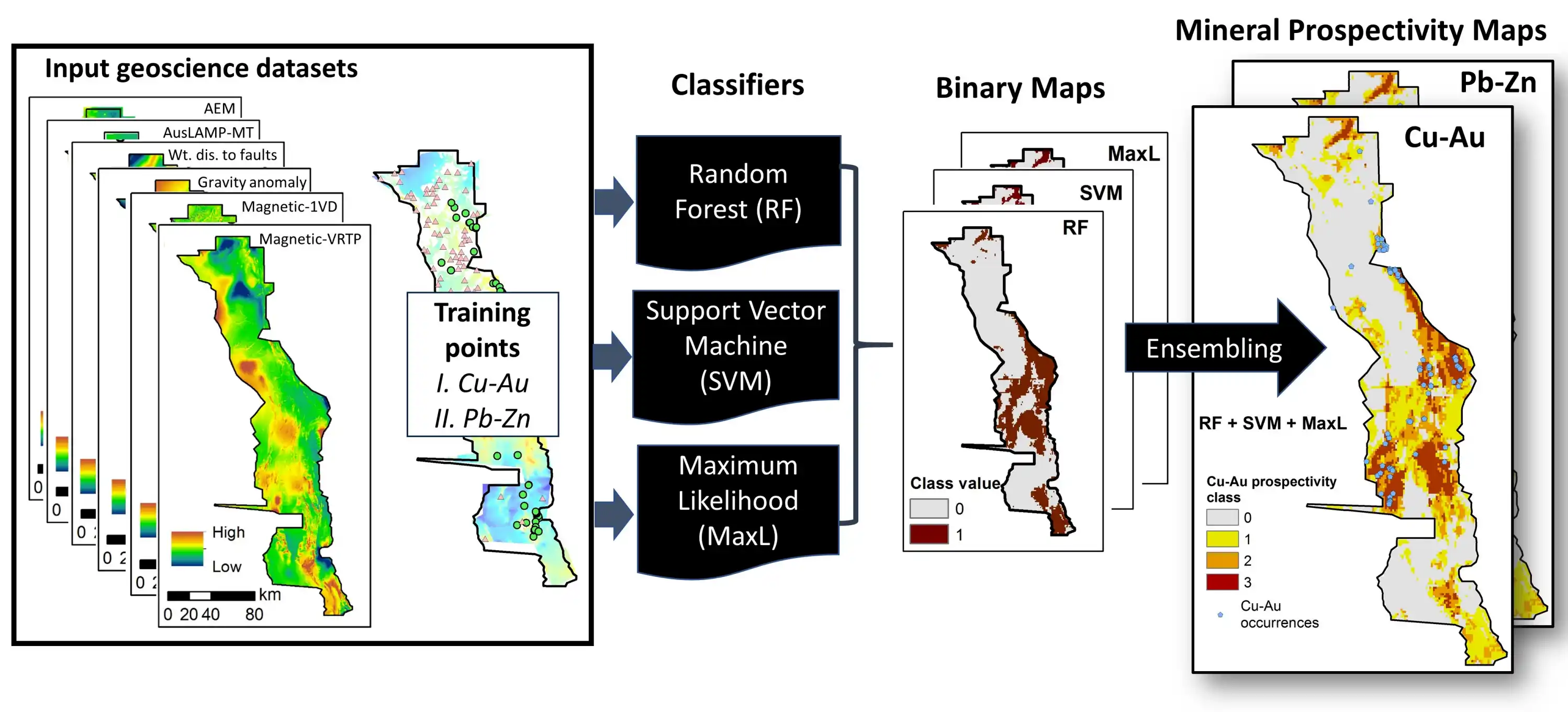
逻辑回归(Logistic Regression, LR)是一种强大的多元统计方法,它被引入成矿预测领域,以克服WofE的主要局限性。 LR 最关键的优势在于:作为一个广义线性模型(GLM),它不需要预测变量(即证据层)之间满足条件独立性的假设。它允许证据层之间存在相关性,这使其在统计上对复杂的地质数据集更加稳健。
从历史背景来看,早在20世纪80年代末至90年代初,地质统计学家(如Agterberg和Bonham-Carter)就开始在同一数据集上并排应用WofE和LR。在这些早期研究中,LR常常被用作一种验证或检查工具,用于评估 WofE 模型中因违反条件独立性假设而可能导致的后果和偏差。
这种从 WofE 到 LR 的过渡,不仅仅是选择了一个“更新”的算法;它是在定量成矿预测领域中一次必要的方法论进展。它解决了由WofE引入的、长期困扰地质学家的核心统计问题(即虚假的CI假设)。学术界普遍认为,逻辑回归是 WofE 方法的“规范泛化”(canonical generalization)。这意味着 WofE 模型实际上是 LR 模型在特定(且通常不成立的)条件下的一个特例。LR 为解决同一科学问题(即多元证据融合预测)提供了一个更通用、更具统计有效性的框架。

科学公式化:逻辑回归作为成矿潜力制图 (MPM) 的工具
定义成矿问题:二元分类
在成矿预测(MPM)中,核心的科学问题可以被精确地表述为:对于一个给定的空间单元(如一个像素或网格单元),综合其所有的地质、地球物理和地球化学观测数据,该单元存在矿床的“概率”是多少?。
这在数学上被构建为一个二元分类问题:
- 因变量 (Y): 是一个二元变量,代表矿床的存在与否(例如,$1$ = 存在矿床,$0$ = 不存在矿床)9。
- 自变量 (X): 是一个向量,包含了所有在该单元上测量的“证据层”数据(例如,到断层的距离、岩性代码、地球化学异常值、遥感蚀变信息等)。
逻辑回归模型天然地适用于解决此类问题。它本身就是一种为模拟二元事件发生概率而设计的分类算法,这与MPM的目标(预测成矿这一二元事件)完美契合。
数学模型:连接地质变量与对数几率
逻辑回归并不直接对概率 $p$ 进行建模,因为它要求输出值在0到1之间,而线性方程的输出是 $(-\infty, +\infty)$。为了解决这个问题,LR模型对概率 $p$ 的 logit 变换(即对数几率,log-odds)进行建模。
Logit 变换的定义是:
$$logit(p) = \ln\left(\frac{p}{1-p}\right)$$
模型的形式是一个广义线性方程:
$$logit(p) = \beta_0 + \beta_1x_1 + \beta_2x_2 + \ldots + \beta_nx_n$$
其中,$p$ 是成矿概率,$x_1, \ldots, x_n$ 是 $n$ 个地质证据变量,$\beta_0$ 是截距,$\beta_1, \ldots, \beta_n$ 是模型系数。
通过求解 $p$,我们可以得到最终的概率预测公式,即Sigmoid函数,它呈现为一条“S形”曲线:
$$p = \frac{1}{1 + e^{-(\beta_0 + \beta_1x_1 + \ldots + \beta_nx_n)}}$$
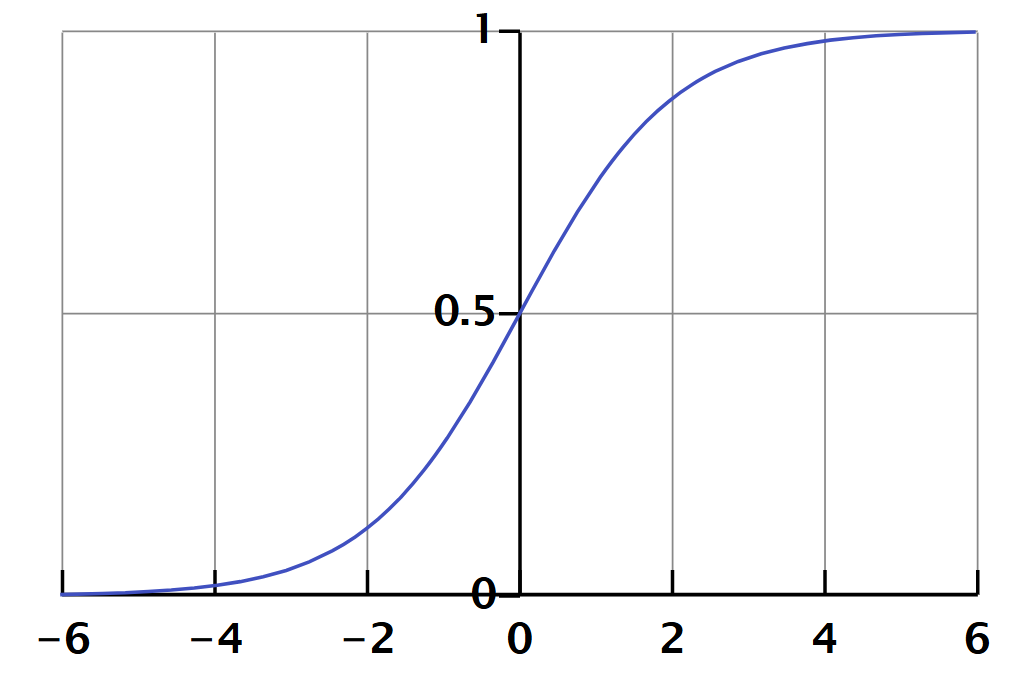
在这个模型中,系数 $\beta_i$ 具有明确的统计意义:它代表了在控制其他所有变量不变的情况下,地质预测变量 $x_i$ 每增加一个单位时,成矿“对数几率”(log-odds)的预期变化量。
“大数据”下的工作流:从假设到成图
在现代 MPM 实践中,应用逻辑回归是一个结合了地质专业知识和数据科学的复杂多步骤工作流。
- 矿床系统分析 (MSA) 与数据收集
- 数据准备与特征工程
- 特征选择与优化
- 模型训练与验证
- 生成成矿概率图 (MPM)
一旦模型被验证为有效,就将训练好的LR方程(即 $p = 1 / (1 + e^{-z})$)应用于研究区的每一个像素。计算机会为每个像素生成一个0到1之间的成矿概率值。最终,将这些概率值渲染成一张“热图”(Heat Map)。这张图(MPM)随后可以根据概率阈值被划分为“低、中、高”潜力区,为后续的野外勘查工作提供直接指导。
逻辑回归的核心价值

系数的可解释性
逻辑回归拥有“易于理解的统计基础”,并产生一个“显式模型”(Explicit Model)——即一个清晰的数学方程。这带来了巨大的实践价值:
- 量化重要性: 地质学家和数据科学家可以检查模型的系数($\beta_i$),以获取关于潜在现象(成矿过程)的知识。
- 验证地质假设: 系数($\beta_i$)量化了每个地质因素(如“断层接近度”或“特定岩性”)对成矿的贡献(正向或负向关联)3。这使得领域专家能够验证模型结果是否“符合地质常理”。如果一个模型在统计上表现良好,但其系数暗示了与既定地质理论相悖的结论,那么这个模型也可能是不可靠的。
在“大数据”和人工智能日益重要的今天,地质勘探领域对“数学严谨且仍能被专家解释”的机器学习方法的需求正在不断增长。逻辑回归完美地填补了这一生态位。它的价值不仅在于预测,更在于推断和知识发现。
概率化输出
与一些仅输出“是/否”分类标签的算法不同,逻辑回归的输出是一个介于0.0到1.0之间的概率估计值。
这个特性在资源勘探中极其有用。勘探决策涉及高昂的成本和风险。一个概率图允许管理者不仅仅是识别“有潜力”的区域,而是能够对所有区域进行排序,并结合勘探成本和预期收益进行复杂的成本-效益分析。
此外,逻辑回归模型相对简单,训练速度快(与深度学习相比),并且通常能提供一个强大的“基线性能”。任何更复杂的模型都必须证明其性能显著优于这个简单、可解释的基线模型,才能证明其应用的合理性。
标准逻辑回归在地质“大数据”中的关键挑战与局限性
尽管逻辑回归具有显著优势,但标准(或称全局)逻辑回归模型在应用于复杂的地质空间“大数据”时,会遇到几个严重的局限性。这些局限性不仅是技术问题,它们代表了模型假设与地质现实之间的根本性科学冲突。
线性假设 vs. 非线性的成矿过程
- 模型假设: 逻辑回归假设自变量($X$)与对数几率(Log-Odds)之间存在线性关系。
- 地质现实: 成矿过程几乎总是复杂的、非线性的。例如,矿床与某个断层的关系可能不是“越近越好”。相反,可能存在一个“最佳距离”范围:太近(如在断层破碎带核心)可能不利于矿质沉淀,太远则超出了流体影响范围。标准的 LR 模型难以捕捉这种复杂的关系。
- 后果: 当数据本质上是非线性时,LR的性能会受到限制,并且可能被那些设计用于处理非线性关系的算法(如随机森林、支持向量机或神经网络)所超越。
“罕见事件”问题:处理极端不平衡数据
- 地质现实: 矿床在地理空间上是极端罕见的事件。在一个MPM数据集中,代表“非矿床”的像素(负样本)可能占到总数据的99.9%甚至更多,而代表“矿床”的像素(正样本)则极其稀少。
- 统计问题: 这是数据驱动MPM面临的最大挑战之一。标准的逻辑回归算法(以及许多其他算法)以最大化总体准确率为目标。在数据极端不平衡时,模型会产生严重的偏差,倾向于预测占主导地位的“非矿床”类别(因为它总是预测“无矿”就能达到99.9%的准确率)。
- 后果: 模型会系统性地低估那些罕见但极其重要的“成矿”事件的发生概率。这使得标准的准确率指标失去意义,并要求使用专门的采样技术或算法来解决。
多源地质空间数据中的“多重共线性”问题
- “大数据”现实: MPM 中的“大数据”意味着整合大量的证据图层。这些图层(变量)之间往往存在高度相关性,即“多重共线性”。例如:航磁异常高值、特定的侵入岩岩性、以及相应的钾异常(来自放射性测量),可能都在描述同一个地质体或成矿事件。
- 统计问题: 逻辑回归的一个基本假设是自变量之间不存在严重的多重共线性。
- 后果: 当多重共线性存在时,虽然模型的整体预测能力不一定会显著下降,但它会导致模型系数($\beta_i$)的估计变得极不稳定(即标准误增大)。这使得研究人员无法再信任这些系数来评估单个预测变量的独立重要性。
- 意义: 这一问题直接削弱了逻辑回归的核心优势——即可解释性。“大数据”的引入加剧了这个问题,使得特征选择或正则化成为必要步骤,以减少数据冗余。
根本性缺陷:空间自相关与空间非平稳性
这是对标准LR模型最深刻的地质统计学挑战,因为它忽略了空间数据的两个本质属性。
- 问题 1 (空间自相关): 包括LR在内的标准回归模型都假设观测值(即像素)是相互独立的。这在地质科学中是根本错误的。根据“地理学第一定律”:空间上邻近的事物总是比远离的事物更相似。这种“空间自相关”特性违反了模型的独立性假设。
- 问题 2 (空间非平稳性): 标准LR是一个“全局模型”。它在整个研究区域上只估计一组系数($\beta_i$),并假设这些系数(即变量间的关系)在任何地方都是恒定不变的。
- 地质现实: 地质过程是“空间非平稳的”。断层与成矿之间的关系,在研究区的一个地方(例如,发育在脆性岩石中)可能非常强烈,但在另一个地方(例如,发育在塑性岩石中)可能毫无关系。
- 后果: 一个“全局”的LR模型只能提供一个“平均化”的、模糊的,甚至可能是误导性的关系描述,从而导致偏差。这是应用非空间模型(LR)于空间数据时所面临的最严重的方法论缺陷。
当然了,有研究人员通过地理加权逻辑回归 (GWLR)来解决解决空间非平稳性的问题,GWLR通过每一个空间位置(像素)计算一个独一无二的LR模型。使用一个“移动窗口”实现这一目标。具体细节感兴趣查看原文吧。我就不在这里赘述了。
结语
我所想要的表格对比终于是在下面完成了。
一个坏消息是这个系列将会很快完结了,好消息是我会在后续出实战教程,手把手教你如何去做(如果我有足够精力的话)。
| 特征 | 信息量法 (IVM) | 证据权法 (WofE) | 逻辑回归 (LR) |
|---|---|---|---|
| 核心假设 | 矿点密度比值可衡量信息量 | 基于贝叶斯定理,权重(W)代表证据强度 | 成矿概率的Logit(对数几率)是预测变量的线性组合 |
| 条件独立性 | 是,隐性假设(简单相加) | 是,方法的关键假设(权重相加) | 否,可以处理相关性强的变量 |
| 透明性 | 高 (白箱) 计算简单直观 |
高 (白箱) 计算和地质意义明确 |
中等 (灰箱) 系数可解释,但模型拟合复杂 |
| 处理非线性 | 能 (间接) 通过数据离散化(分箱) |
能 (间接) 通过数据离散化(分箱) |
能 (显式) 可引入多项式项或进行分箱 |
| 处理因素交互 | 差 传统模型不考虑交互 |
差 传统模型不考虑交互 |
能 (显式) 可在模型中主动添加交互项 |
| 数据需求 | 离散化图层 (二元或多元) 矿点位置 |
离散化图层 (二元或多元) 矿点位置;可处理缺失数据 |
可处理连续和离散变量 矿点和非矿点位置 (Non-deposits) |
| 主要优势 | 1. 极其简单,易于计算和理解 2. 透明度高 |
1. 理论基础坚实 (贝叶斯) 2. 透明度高,地质意义明确 3. 稳健,被广泛验证和接受 |
1. 不要求条件独立性 2. 可处理连续变量 3. 可显式处理因素交互作用 |
| 主要劣势 | 1. 依赖条件独立性假设 2. 传统模型假设因素同等重要 3. 统计上不如WofE稳健 |
1. 严格依赖条件独立性假设 2. 无法处理因素交互 3. 需将连续数据二元化,损失信息 |
1. 需要非矿点样本 2. 透明性稍差 3. 易受“共线性”问题干扰 |

科学探索永无止境,本文仅为笔者个人学习总结。因知识所限,文中若有不当之处,敬请方家斧正。
参考内容
- Zhang, D., Ren, N., & Hou, X. (2018). An improved logistic regression model based on a spatially weighted technique (ILRBSWT v1. 0) and its application to mineral prospectivity mapping. Geoscientific Model Development, 11(6), 2525-2539.
- Kost, S., Rheinbach, O., & Schaeben, H. (2021). Using logistic regression model selection towards interpretable machine learning in mineral prospectivity modeling. Geochemistry, 81(4), 125826.
- Fu, Z., Zheng, X., Yan, Y., Xu, X., Zhou, F., Li, X., … & Mai, W. (2025). The Evolution of Machine Learning in Large-Scale Mineral Prospectivity Prediction: A Decade of Innovation (2016–2025). Minerals.
- Xiong, Y., & Zuo, R. (2018). GIS-based rare events logistic regression for mineral prospectivity mapping. Computers & Geosciences, 111, 18-25.