

送给师弟师妹最好的礼物!全组文献自由就靠这个脚本了
前言科研通如果你不知道是什么的话,其实他就是一个文献求助平台。某些期刊的文献你无法下载的话,可以在那里发布文献求助,可以很快获取完整文献。对于研究人员而言,我还是很推荐的。
脚本的话是去年写的了,主要还是在科研通上签到太麻烦了,我就尝试使用自动化的方法寻求解决方案了。
其实更多的是,我个人信奉一个理论:如果一个事情需要重复做,且占用时间超过 15 秒,那么你就需要考虑自动化去完成了。
当时我集中弄了两个自动化的解决方案:
基于本地浏览器的可视化编程自动化脚本(只能实现单用户签到)
基于 Python 自动化签到脚本(实现多用户批量同时签到,给你的师弟师妹最好的礼物🤣)
这两个解决方案各有优缺点,我会在最后简单说明,对于懒得部署使用的同学,也可以填写我创建的收集表,提供相关的信息,我可以公益在服务器上批量签到。
解决方案本地浏览器这个解决方案是基于本地浏览器进行的,是利用了开源的浏览器插件 Automa 。这个插件可以实现模块化,可视化的编程实现在浏览器上的任何自动化操作。
插件安装去官网访问安装即可,Free ~
我的实现思路很简单
首先在后台打开新的标签页
访问科 ...

大数据成矿预测系列(九) | 数据的“自我画像”:自编码器如何实现非监督下的“特征学习”
前言这部分内容会比较短,主要是简单说明一下自编码器。当然,自编码器其实更多的是在地球化学异常识别的情况下更加得心应手,所以这篇文章其实和“成矿预测”稍微有点偏题,不过终归而言,它们也是异常识别的一部分。
之前提到,现代矿产勘查正在经历一场变革,从传统的经验驱动模式转向数据驱动的定量预测 。这一转变的核心驱动力在于多源地质“大数据”的爆发。然而,地质数据并非简单的“大数据”集合,其固有的复杂性对传统分析方法构成了严峻的“科学问题”:
高维性与非线性: 地球化学数据通常包含几十种元素的浓度信息 。这些元素在复杂的成矿过程中,其相互关系(如协同富集或拮抗)往往呈现高度非线性的特征 ,远非简单的线性相关所能概括。
强噪声与数据缺失: 地质勘查数据,无论是岩石、土壤还是水系沉积物样本,在采集和分析过程中不可避免地会引入噪声、异常值甚至数据缺失 。这些干扰严重掩盖了与成矿相关的真实地质信号 。
空间自相关性: 地质现象在空间上是连续的,相邻的样本点通常具有相似的地质属性 。这种空间依赖性是地质统计学的基石,但常被传统的数据挖掘算法所忽略 。
非正态分布: 元素浓度等地质变量通常不服从 ...

大数据成矿预测系列(八) | 从定性到概率:逻辑回归——地质统计学派的“集大成者”
前言这部分应该和证据权重法放在一起,建议先看证据权重法再看这个。
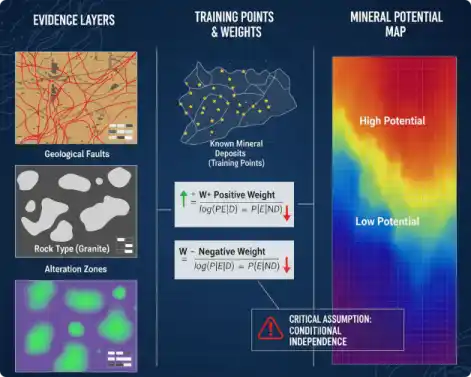
在众多早期的概率性方法中,证据权重法(Weights of Evidence, WofE)是应用最广泛、最被地质学家所接受的方法之一。WofE基于贝叶斯定理的对数线性形式,通过计算权重($W^+$ 和 $W^-$)来衡量每一个证据层(如“靠近断层”)与已知矿床点之间的空间关联强度。
然而,WofE方法的有效性建立在一个极其严苛且关键的统计假设之上:所有证据层相对于矿床的发生是“条件独立的”(Conditional Independence, CI)。在地质现实中,这一假设几乎总是被违背的。WofE的权重值提供了这样一种直观的度量,使其易于被非统计学专家所接受。这在地质直觉和统计严谨性之间造成了一种长期的紧张关系。
逻辑回归(Logistic Regression, LR)的出现,正是为了解决WofE模型中“条件独立性”假设这一核心科学难题。
逻辑回归的兴起:针对相关性证据的稳健解决方案逻辑回归(Logistic Regression, LR)是一种强大的多元统计方法,它被引入成矿预测领域,以克服WofE的主要局限性。 ...

大数据成矿预测系列(七) | 经典模型的“孪生兄弟”:信息量法 (IVM) 深度解析
前言这部分内容应该是和前面的经典成矿预测模型“证据权重法”放在同一个地方的,我写着写着进度快了点,给他忘了🤦♂️。现在慢慢补上,虽然这个系列的章节序号可能会从此有些混乱(是的,典型的自己给自己挖的“屎山”)。
好吧,现在有请我们的主角——信息量法 (Information Value Method, IVM),它同样是矿产资源定量预测领域的经典方法之一,常与证据权重法并列,被广泛用于成矿靶区评价与优选。
起源:数学地质学派信息量法 (Information Value Method, IVM) 作为一种定量预测工具,其“地质血统”十分清晰。信息量法最早“应用于区域矿产预测, 是由前苏联数学地质学家 E.B.维索科奥斯特罗夫斯卡娅于 1968 年首次提出,随后 N.N.恰金在 1969 年进一步完善。其设计初衷就是为了解决矿产勘查中的定量化和预测问题。 中国地质学家赵鹏大等人在 20 世纪 80 年代将其引入国内,并在矿床统计预测中取得显著成效。
范式传播:地质灾害领域的应用尽管 IVM 起源于矿产预测,但其作为一种通用的 GIS 空间统计方法被广泛传播和应用,则主要归功于其 ...

大数据成矿预测系列(六) | 从“看图像”到“读结构”:GCN如何赋能地质“图谱”推理
前言在前文中,我们介绍了卷积神经网络(CNN)为成矿预测带来了新的契机,并在一定程度上突破了传统机器学习模型的局限。卷积神经网络无疑扮演了先驱者的角色。其作为一种强大的“基于图像的模型” ,其核心优势在于能够像“看照片”一样处理和分析地质图件。
尽管在较为完善的特征工程支持下,卷积神经网络在多源异构数据集上的应用具有一定的可行性,但它仍存在一些难以克服的固有缺陷。正是为了应对这些挑战,我们引出了这一部分的主角——图卷积神经网络(GCN)。
CNN的成就: 栅格数据中的“像素智能”CNN通过其“卷积核”设计,能够“提取局部的有意义特征并捕捉空间模式” 。无论是在遥感影像中自动进行岩性填图 ,还是在地球物理和地球化学栅格数据中识别环状或线性异常,CNN都展示了其强大的局部特征提取能力 。在三维(3D)成矿预测中,3D-CNN模型也能从3D预测层中提取空间分布特征 。
这种能力,我们可以称之为“像素智能”。CNN就像一位“近视”的图像专家,它能极其敏锐地识别小范围内的纹理和模式,例如在“短程区域”内提取丰富的光谱与空间特征 。
(1) “近视”的感知——受限的局部感受野CNN ...

你的模型在“作弊”吗?深度解析机器学习中“数据泄露”的隐蔽陷阱
前言本文将探讨在日常机器学习应用过程中可能出现的数据泄露问题。这个问题在业界通常被称为 “目标泄露”(Target Leakage) 或 “数据窥探”(Data Snooping)。这一问题在相关机器学习教程中鲜有专门讨论,甚至许多从事交叉学科研究的初学人员也未必了解。掌握这一点后,读者将能够更容易地识别出部分论文中存在的错误,或那些对相关细节缺乏严谨说明的情况。
2023 年的一项研究发现,数据泄露是“基于机器学习 的科学中普遍存在的失败模式”,影响了 17 个学科的至少 294 篇学术出版物,并导致了潜在的可重复性危机。
我个人认为目前这个情况是保守了(苦笑
什么是数据泄露数据泄露的核心定义是在模型训练过程中使用了在预测时不应获得的信息 。这种”额外信息”可能来自未来数据、测试集、目标变量本身或全局统计量。这是一种程序性错误,模型通过获取未来或特权信息来有效地“作弊” 。这种现象一般是微妙且间接的,很多机器学习使用者有可能会忽略的存在。
从信息论角度看,数据泄露创造了一种”时空穿越”效应——模型在训练时获得了本不应在预测时点存在的知识。这导致模型的学习目标发生偏离:它不再学 ...
大数据成矿预测系列(五) | 告别特征工程:卷积神经网络(CNN)如何实现“端到端”成矿预测
前言前面的内容讲述了,机器学习为地质学家寻找矿产资源开辟了新的契机与范式,并成功克服了传统地学统计模型(如证据权重法)的部分局限。然而,我们也必须正视——机器学习依然存在一些难以彻底消除的不足。这些不足促使部分研究者在成矿预测领域中积极探索,并尝试引入其他方法加以改进。
这也就是我们这部分内容要讲述的深度学习——卷积神经网络 (Convolutional Neural Network, CNN) 的故事。当然在开始讲述我们的主要内容之前,需要先说明一下传统的机器学习的“枷锁”。
机器学习的“烦恼”以支持向量机 (Support Vector Machines)、随机森林 (Random Forests, RF) 和逻辑回归 (Logistic Regression) 为代表的经典机器学习模型,在过去十年中为定量化找矿预测做出了巨大贡献 。然而,这些模型的共同点在于,它们无法直接“消化”原始的地质图件。它们需要的是结构化的、量化的输入,即一系列被称为“证据图层”或“特征图”的专题地图。特征工程,就是地质学家将自己的专业知识和成矿理论,手动转化为这些机器可读的证据图层的过程 。
这 ...

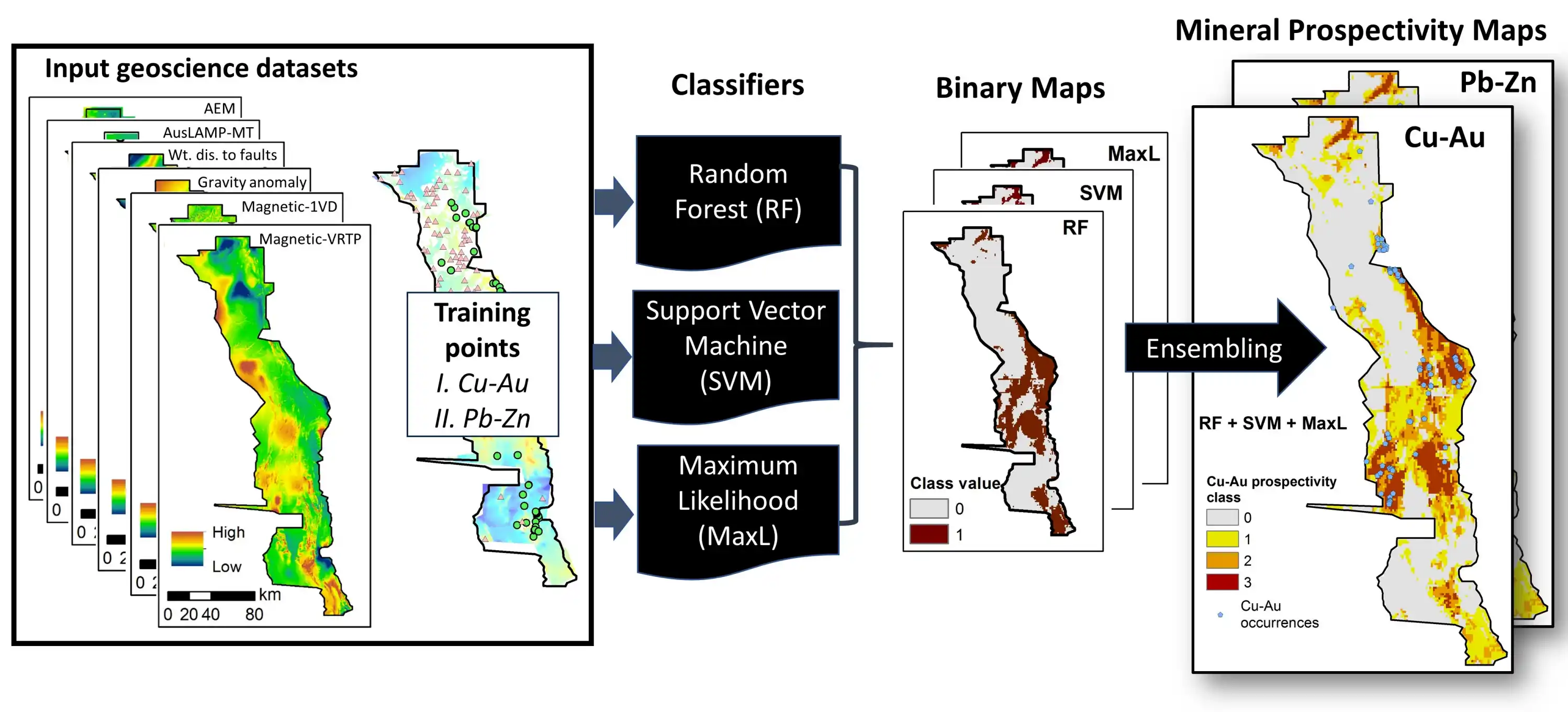
大数据成矿预测系列(四) | 成矿预测的“主力军”:随机森林与支持向量机深度解析
前言随着地球科学进入大数据时代,传统的矿产勘查方法正面临着一场深刻的变革。从传统的统计学模型到现代的机器学习模型,成矿预测正经历着范式的转变。现代勘探工作流需要整合来源多样、结构复杂的海量数据集,包括地质填图、地球物理、地球化学以及高分辨率遥感影像 (当然还有钻孔数据等其他数据)。在这一背景下,机器学习是将这些海量数据转化为精准成矿预测图(Mineral Prospectivity Mapping, MPM)的核心引擎。
当然,从数据角度来看,地质大数据可以分为结构化数据,半结构换数据和非结构化数据。数据相关的内容我会在后续专门开一个系列讲述。这并不是这篇文章的重点。欢迎持续关注 “码上地球——数学地球科学” 获取后续内容。
在众多算法中,随机森林(Random Forest, RF)与支持向量机(Support Vector Machine, SVM)已成为该领域应用最广泛、最核心的两大“主力军” 。它们凭借强大的非线性关系建模能力,在地学数据分析中扮演着举足轻重的角色(论文中随处可见😂)。
本文旨在简单阐述其工作原理,讨论在成矿预测这一特定场景下,哪种算法更能应对 ...
大数据成矿预测系列(三) | 从统计模型到机器学习:为何机器学习是成矿预测的新前沿?
前言矿产勘查的本质上就是是一场在巨大的不确定性中寻求确定性的过程。从早期探矿依赖个人经验和直觉的“相矿”,到后来基于地质理论的知识驱动模型。在漫长的发展中,证据权重法(Weights of Evidence, WofE)的出现开创性地引入了数据驱动的理念,为在地理信息系统(GIS)环境下系统性地整合多源地学信息、进行定量化的成矿预测提供了第一个强大而客观的框架。
尽管证据权重法具有不可磨灭的历史地位,但其赖以成立的数学基石——“条件独立性假设”——与复杂且相互关联的真实成矿地质系统存在着根本性的矛盾。随着现代地球科学进入“大数据”时代,高维度、多源地学数据的爆发式增长使得这一核心假设的局限性日益凸显,甚至达到了其理论框架的断裂点。这一深刻的矛盾,催生并论证了一场势在必行的范式革命:向机器学习的转型。
前排说明:本文旨在探讨地学大数据的发展如何推动成矿预测的进步,而并非深入展开具体算法、数学原理、操作方法,或其在地质大数据中的详细应用。若您对相关算法的使用方法及其在地质大数据中的实践感兴趣,欢迎持续关注 “码上地球——数学地球科学” 获取后续内容。
现实对证据权重法的重拳在 ...

大数据成矿预测系列(二) | 证据权重法如何克服自身局限?
前言承接上文,证据权重法 (WofE) 自问世以来,虽为成矿预测带来了革命性的进步,但其与生俱来的理论缺陷在复杂的实际应用中成为了无法回避的“阿喀琉斯之踵”。正是为了弥补这些裂痕,无数科研工作者前赴后继,开启了一段漫长而富有挑战的“打补丁”征程。
证据权重法的“阿喀琉斯之踵”首先,我们需要先了解为什么要进一步改进证据权重法,或者需要先了解证据权重法的固体有缺陷。主要包括以下几个方面:
致命缺陷:难以满足的“条件独立”假设证据权重法 (WofE) 模型最核心、也最备受诟病的理论基石是:所有证据层(如地质构造、地球化学异常、地球物理特征等)之间必须相互条件独立。
然而,在真实的地质系统中,成矿过程是一个复杂的、多因素相互耦合的系统,各种地质现象之间往往存在着紧密的内在联系和因果关系。例如,断裂构造常常是热液活动的通道,因此会伴生明显的蚀变带和地球化学异常。这些证据因子在空间上高度相关,并非彼此独立。
违背该假设会带来一系列严重后果:
系统性的向上偏倚(Upward Bias):这是最具破坏性的后果。当证据层相关时,模型会对同一信息的不同表现形式进行“重复计算”,导致对潜在成矿区的 ...