正则表达式
前言
正则表达式是去年夏天我就想说明的东西了,不过一直鸽到现在,这部分将会记录正则表达式的基本语法以及一个C#应用实例。
关于正则表达式学习个人的相关推荐:
关于正则表达式测试的网站:
关于正则表达式在线生成工具(1/2不表示排名):
正则表达式
关于正则表达式百度百科的定义如下
正则表达式,又称规则表达式。**(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
通俗来说,就是我们常用的Word搜索功能的加强版,它可以通过特定的语法格式来实现文本搜索(匹配),来满足我们期望找到的文本。
Regular expression(正则表达式)这个词比较拗口,常使用缩写的术语“regex”或“regexp”
基本语法
基本匹配
正则表达式的基本匹配是我们常规的搜索类型,即所见即所得,例如:输入love,则匹配到所有包含该字符的字符串。

正则表达式是大小写敏感的,所以,如果输入Love,它不会匹配上图结果

关于图中在输入表达式前面
/符号的意义,后面会解释,默认我们输入正则表达式的格式为/这里是我们输入的正则表达式/g。
元字符
正则表达式由元字符构成。元字符可以理解为正则表达式控制查找字符串规则的字符,它们具有一定的含义,类似于代码中if表示的是如果的意思。关于一些常规元字符的解释:
| 元字符 | 描述 |
|---|---|
. |
句号匹配任意单个字符除了换行符。 |
[] |
字符种类。匹配方括号内的任意字符。 |
[^] |
否定的字符种类。匹配除了方括号里的任意字符 |
* |
匹配 $\geq 0$个重复的在*号之前的字符。 |
+ |
匹配 $\geq 1$个重复的+号前的字符。 |
? |
标记?之前的字符为可选. |
{n,m} |
匹配 num个大括号之前的字符或字符集 ( $n \leq num \leq m$ ). |
(xyz) |
字符集,匹配与 xyz 完全相等的字符串. |
| ` | ` |
\ |
转义字符,用于匹配一些保留的字符 `[ ] ( ) { } . * + ? ^ $ \ |
^ |
从开始行开始匹配. |
$ |
从末端开始匹配. |
点运算符.
.运算符是一个任意字符的占位符(除换行符),例如:.ve表示匹配三个字符(.表示任意字符的占位符),以任意字符开头的且后面跟着ve字符的字符。

字符集
字符集表示的是字符的集合,它通过使用方括号([])来表示一个字符集。通过在[]中输入字符来表示匹配字符范围,需要注意的是:方括号中不关心其字符顺序,例如:[a-z]表示的意思是匹配字符集中小写字母a到z的所有字符。如下图:

-表示两者的区间,同样的你也可以使用[A-Z]表示所有大写字母A到z的所有字符,或者[0-9]表示所有数值。再例如:[Ll]ove,表示的匹配Love或者love字符,因为l和L字符在字符集中,所以结果:

否定字符集
否定字符集的意思可以通过^来表示不包含字符集中某些字符,例如:[^L]ove表示的意思是不匹配以大写字符L开头且其后跟着字符ove的字符串。示例:

需要注意的是字符
^如果包含在字符集[]中,则其含义是不同的,例如:[^L]和^L的含义是不同的。
重复次数
元字符*,?,+表示的是对字符出现次数的限制。
元字符
**表示的是匹配在*号之前的字符的出现次数大于等于0次的字符。例如:a*love表示的意思匹配所有a字符开头且其出现次数大于等于0次,且后面跟着love的字符串。示例:
元字符
++表示的是匹配在+号之前的字符出现次数大于或者等于1次的字符。例如:a+love表示的意思是匹配所有以a字符开头的且a字符的出现次数大于等于1次,且后面跟着love的字符串。示例:
元字符
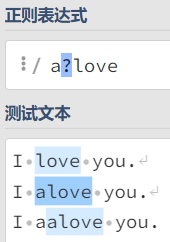
??表示的是匹配在?之前的字符出现的次数为 1 次或者 0 次的字符。例如:a?love表示的意思是匹配所有以字符a出现次数为 0 或者 1 次开头的,且其后面跟随love的字符串。示例:


{}
{}表示的是匹配其前面字符指定的出现次数。例如:a{1,2}love表示的意思是匹配以a字符开始的且a字符的出现次数为 1 次或者 2次的,且其后面跟着love字符的字符串。示例:

(...)特征标记群
()表示的是在()里的字符是一个组合。这样描述不是很直观,如上述示例:a{1,2}love,表示的a字符的出现次数是 1 次或者 2次,但是如果我们希望ab字符出现的次数是 1 次或者 2次就会很棘手,或许有的伙伴认为可以这样:a{1,2}b{1,2}love,示例:

实际上,可以看到第三行的字符abablove也是我们想要匹配的字符,而不是第四行的aabblove字符。这个时候就需要使用特征标记群,例如:(ab){1,2}love,表示的意思是以字符群ab开始的且其出现次数为 1 次或者 2 次,且其后面跟着字符love的字符串。示例:

|或运算符
同一般的计算机语言,**|表示或者**。例如:(L|l)ove表示匹配以L或者l开头的,且其后跟着ove的字符串。示例:

转义字符
有的时候我们希望匹配的特殊字符是正则表达式的元字符之类的字符,例如我们希望匹配.字符,如果不使用转义字符,则默认被识别为正则表达式的.元字符来处理。所以我们需要使用\来表示转义字符,其后面跟的字符表示转义我们要使用的字符。例如:\.love表示匹配以.开始且后跟着love的字符串。示例:

同理,其他字符也是,例如:\[表示匹配字符[,\+表示匹配字符+等等。
锚点
如果我们希望专门匹配一段文字的开头和末尾的特定字符就离不开锚点。
^开头锚点^表示开头锚点。例如:^(T|l)ove表示匹配在一段文字的开头其字符为Love或者love的字符串。示例:
需要注意的是锚点,在不改变匹配规则的情况下,默认只匹配一段文字的开头和末尾字符串。例如下图,即使第一个字符不匹配,也不会匹配到第二个字符
关于什么是匹配规则,下面的部分会说明
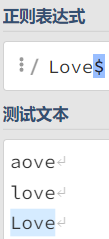
$结尾锚点结尾锚点也同理,只匹配
$前面字符与一段文字的最后一个字符串比较。例如:love$,表示匹配一段位置最后一个字符串是否包含love字符。示例:


简写字符集
对于一些常用的字符集,例如[a-z],[A-Z],[0-9]等字符集,官方做了整合,使用如下简单字符表达式来表示该公式:
| 简写 | 描述 |
|---|---|
. |
除换行符外的所有字符 |
\w |
匹配所有字母数字,等同于 [a-zA-Z0-9_] |
\W |
匹配所有非字母数字,即符号,等同于: [^\w] |
\d |
匹配数字: [0-9] |
\D |
匹配非数字: [^\d] |
\s |
匹配所有空格字符,等同于: [\t\n\f\r\p{Z}] |
\S |
匹配所有非空格字符: [^\s] |
\f |
匹配一个换页符 |
\n |
匹配一个换行符 |
\r |
匹配一个回车符 |
\t |
匹配一个制表符 |
\v |
匹配一个垂直制表符 |
\p |
匹配 CRLF(等同于 \r\n),用来匹配 DOS 行终止符 |
零宽度断言(前后预查)
关于零宽断言的定义,如下斜体引用自百度百科:
零宽断言是正则表达式中的一种方法,正则表达式在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。
我个人理解为是一种筛选字符串的规则,当我们规则某个字符出现为真或者假时则执行的正则表达式取值,类似于将基本的真假判断分支不同处理结果,根据结果引入字符筛选的正则表达式。
它是另一种形式的占位符,是一种条件零宽度占位符,所谓零宽度是指的是返回的结果中不包含该断言内容,例如:(?<=\$)[0-9\.]*表示的意思是:判断字符的开头是否存在字符$,且其后面含有 0 到 9 的,且最后跟着字符.的字符串。示例:

如上示例使用的是 正后发断言,关于零宽度断言的分类:
| 符号 | 描述 |
|---|---|
?= |
正先行断言-存在 |
?! |
负先行断言-排除 |
?<= |
正后发断言-存在 |
?<! |
负后发断言-排除 |
?=...正先行断言
**?=正先行断言,表示第一部分表达式之后必须跟着?=定义的表达式。返回结果只包含满足条件的第一部分表达式匹配的内容,定义正先行断言需要使用()**。例如:love(?=\.)表示满足字符love后面存在字符.匹配的字符串,其匹配字符串不包含正先行断言中的内容,即.。示例:

?!...负先行断言
?!负先行断言,使用格式参考正先行断言,其作用是匹配不包含负先行断言的内容,理解为正先行断言的取反。例如:love(?!\.),表示的意思是匹配不包含字符.的,且其前面的字符为love的字符串。示例:

?<=...正后发断言
?<=正后发断言,与正先行断言的区别是匹配的正则表达式要在断言的后面,例如:(?<=\.)love表示的意思是匹配目标字符串前面存在字符.且包含love的字符串。示例:

?<!...负后发断言
?<!正后发断言,与负先行断言的区别是匹配的正则表达式要在断言的后面,例如:(?<!\.)love表示的意思匹配目标字符串前面不存在字符.且包含字符love的字符。示例:

Lookarounds 是零宽度断言的英文
匹配规则(标志)
匹配规则是一种匹配修正符,用来指控匹配的模式,它也是正则表达式的一部分。例如:
| 标志 | 描述 |
|---|---|
i |
忽略大小写。 |
g |
全局搜索。 |
m |
多行修饰符:锚点元字符 ^ $ 工作范围在每行的起始。 |
实际完整的正则表达式的格式为:/这里写正则表达式/匹配规则,一般默认为/我们在这里写正则表达式/g。
当然实际上对于现在的正则表达式还有很多其他的匹配规则,例如下图,详细的请自行百度或者谷歌查询。

忽略大小写
可以通过在匹配规则中添加i来表示匹配字符串时忽略大小写。例如:/love/gi表示匹配不区分大小的包含love的字符。示例:

i是 insensitive(不区分大小写)的缩写
全局搜索
g表示匹配的返回结果是全部的匹配结果,而不是仅返回第一个匹配的字符。例如:/love/表示仅返回匹配的第一个字符。示例:

但是如果使用/love/g,则示例:

g是 global 的缩写
多行修饰符
m是表示执行多行匹配,这么说可能不直观,如图前面说明的锚点,对于开头或者结尾锚点,仅仅匹配一段文字的最后或者末尾一个字符串,但是如果使用了m,即多行修饰符,则会进行多行的开头和结尾匹配。例如:/^love/gm表示的意思是匹配每一行的开头包含love的字符串。示例:

m是 muti line的缩写
贪婪匹配和惰性匹配(Greedy vs lazy matching)
正则表达式默认使用贪婪匹配,即尽可能的匹配更长的字符串,可以通过使用?将贪婪匹配模式转换为惰性匹配模式。例如:.*in表示的意思是:匹配空字符字符出现 0 次或者更多次的且后面包含字符in的字符串,这也是正则表达式默认我贪婪匹配模式。示例:

但是使用.*?in表示尽可能的匹配多段字符,示例:

返回了两个字符段,而不是默认的一段长字符段。

正则表达式应用实例
本实例使用C#代码,基于 Winform 来实现。
实例内容:利用正则表达式来实现规定用户注册账户的时候,用户名仅限于英文字母和数字以及下划线的组合;而密码仅限于字母和数字的组合。
使用 Winform 简单设计一个如下的注册窗口
然后在注册按钮的事件中,使用如下代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25string pattern1 = @"^\w+$";
string pattern2 = @"^[A-Za-z0-9]+$";
if (textBox1.Text == "" || textBox2.Text == "")
{
MessageBox.Show("请输入用户名或者密码");
}
else
{
if (Regex.IsMatch(textBox1.Text, pattern1) == false)
{
MessageBox.Show("用户名格式不正确");
}
else
{
if (Regex.IsMatch(textBox2.Text, pattern2) == false)
{
MessageBox.Show("密码格式不正确");
}
else
{
MessageBox.Show("注册成功");
}
}
}当我们输入包含
?字符的用户名时,则弹出错误提醒:
如果输入含有
?字符的密码时,则弹出错误提醒:
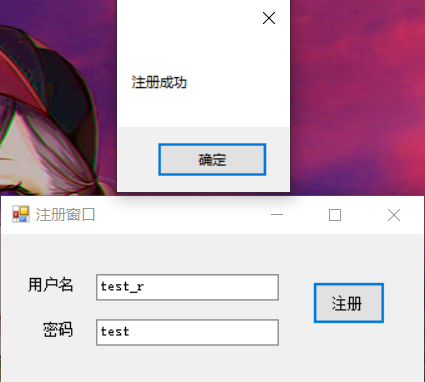
只有输入正确的用户名和密码格式,才会注册成功:



常用正则表达式
校验数字的表达式
- 数字:**
^[0-9]\*$** - n位的数字:**
^\d{n}$** - 至少n位的数字:**
^\d{n,}$** - m-n位的数字:**
^\d{m,n}$** - 零和非零开头的数字:**
^(0|[1-9][0-9]\*)$** - 非零开头的最多带两位小数的数字:**
^([1-9][0-9]\*)+(\.[0-9]{1,2})?$** - 带1-2位小数的正数或负数:**
^(\-)?\d+(\.\d{1,2})$** - 正数、负数、和小数:**
^(\-|\+)?\d+(\.\d+)?$** - 有两位小数的正实数:**
^[0-9]+(\.[0-9]{2})?$** - 有1~3位小数的正实数:**
^[0-9]+(\.[0-9]{1,3})?$** - 非零的正整数:**
^[1-9]\d\*$或^([1-9][0-9]\*){1,3}$或^\+?[1-9][0-9]\*$** - 非零的负整数:**
^\-[1-9][]0-9"\*$或^-[1-9]\d\*$** - 非负整数:**
^\d+$或^[1-9]\d\*|0$** - 非正整数:**
^-[1-9]\d\*|0$或^((-\d+)|(0+))$** - 非负浮点数:**
^\d+(\.\d+)?$或^[1-9]\d\*\.\d\*|0\.\d\*[1-9]\d\*|0?\.0+|0$** - 非正浮点数:**
^((-\d+(\.\d+)?)|(0+(\.0+)?))$或^(-([1-9]\d\*\.\d\*|0\.\d\*[1-9]\d\*))|0?\.0+|0$** - 正浮点数:**
^[1-9]\d\*\.\d\*|0\.\d\*[1-9]\d\*$或^(([0-9]+\.[0-9]\*[1-9][0-9]\*)|([0-9]\*[1-9][0-9]\*\.[0-9]+)|([0-9]\*[1-9][0-9]\*))$** - 负浮点数:**
^-([1-9]\d\*\.\d\*|0\.\d\*[1-9]\d\*)$或^(-(([0-9]+\.[0-9]\*[1-9][0-9]\*)|([0-9]\*[1-9][0-9]\*\.[0-9]+)|([0-9]\*[1-9][0-9]\*)))$** - 浮点数:**
^(-?\d+)(\.\d+)?$或^-?([1-9]\d\*\.\d\*|0\.\d\*[1-9]\d\*|0?\.0+|0)$**
校验字符的表达式
- 汉字:**
^[\u4e00-\u9fa5]{0,}$** - 英文和数字:**
^[A-Za-z0-9]+$或^[A-Za-z0-9]{4,40}$** - 长度为3-20的所有字符:**
^.{3,20}$** - 由26个英文字母组成的字符串:**
^[A-Za-z]+$** - 由26个大写英文字母组成的字符串:**
^[A-Z]+$** - 由26个小写英文字母组成的字符串:**
^[a-z]+$** - 由数字和26个英文字母组成的字符串:**
^[A-Za-z0-9]+$** - 由数字、26个英文字母或者下划线组成的字符串:**
^\w+$或^\w{3,20}$** - 中文、英文、数字包括下划线:**
^[\u4E00-\u9FA5A-Za-z0-9_]+$** - 中文、英文、数字但不包括下划线等符号:**
^[\u4E00-\u9FA5A-Za-z0-9]+$或^[\u4E00-\u9FA5A-Za-z0-9]{2,20}$** - 可以输入含有^%&’,;=? $"等字符:**
[^%&',;=?$\x22]+** - 禁止输入含有
的字符:**`[^\x22]+`**
特殊需求表达式
- Email地址:**
^\w+([-+.]\w+)\*@\w+([-.]\w+)\*\.\w+([-.]\w+)\*$** - 域名:**
[a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.?** - InternetURL:**
[a-zA-z]+://[^\s]\*或^https://([\w-]+\.)+[\w-]+(/[\w-./?%&=]\*)?$** - 手机号码:**
^(13[0-9]|14[5|7]|15[0|1|2|3|4|5|6|7|8|9]|18[0|1|2|3|5|6|7|8|9])\d{8}$** - 电话号码(“XXX-XXXXXXX”、”XXXX-XXXXXXXX”、”XXX-XXXXXXX”、”XXX-XXXXXXXX”、”XXXXXXX”和”XXXXXXXX):**
^(\(\d{3,4}-)|\d{3.4}-)?\d{7,8}$** - 国内电话号码(0511-4405222、021-87888822):**
\d{3}-\d{8}|\d{4}-\d{7}** - 电话号码正则表达式(支持手机号码,3-4位区号,7-8位直播号码,1-4位分机号):
((\d{11})|^((\d{7,8})|(\d{4}|\d{3})-(\d{7,8})|(\d{4}|\d{3})-(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1})|(\d{7,8})-(\d{4}|\d{3}|\d{2}|\d{1}))$) - 身份证号(15位、18位数字),最后一位是校验位,可能为数字或字符X:**
(^\d{15}$)|(^\d{18}$)|(^\d{17}(\d|X|x)$)** - 帐号是否合法(字母开头,允许5-16字节,允许字母数字下划线):**
^[a-zA-Z][a-zA-Z0-9_]{4,15}$** - 密码(以字母开头,长度在6~18之间,只能包含字母、数字和下划线):**
^[a-zA-Z]\w{5,17}$** - 强密码(必须包含大小写字母和数字的组合,不能使用特殊字符,长度在 8-10 之间):**
^(?=.\*\d)(?=.\*[a-z])(?=.\*[A-Z])[a-zA-Z0-9]{8,10}$** - 强密码(必须包含大小写字母和数字的组合,可以使用特殊字符,长度在8-10之间):**
^(?=.\*\d)(?=.\*[a-z])(?=.\*[A-Z]).{8,10}$** - 日期格式:**
^\d{4}-\d{1,2}-\d{1,2}** - 一年的12个月(01~09和1~12):**
^(0?[1-9]|1[0-2])$** - 一个月的31天(01~09和1~31):**
^((0?[1-9])|((1|2)[0-9])|30|31)$** - 钱的输入格式:
- 有四种钱的表示形式我们可以接受:”10000.00” 和 “10,000.00”, 和没有 “分” 的 “10000” 和 “10,000”:**
^[1-9][0-9]\*$** - 这表示任意一个不以0开头的数字,但是,这也意味着一个字符”0”不通过,所以我们采用下面的形式:**
^(0|[1-9][0-9]\*)$** - 一个0或者一个不以0开头的数字.我们还可以允许开头有一个负号:**
^(0|-?[1-9][0-9]\*)$** - 这表示一个0或者一个可能为负的开头不为0的数字.让用户以0开头好了.把负号的也去掉,因为钱总不能是负的吧。下面我们要加的是说明可能的小数部分:**
^[0-9]+(.[0-9]+)?$** - 必须说明的是,小数点后面至少应该有1位数,所以”10.”是不通过的,但是 “10” 和 “10.2” 是通过的:**
^[0-9]+(.[0-9]{2})?$** - 这样我们规定小数点后面必须有两位,如果你认为太苛刻了,可以这样:**
^[0-9]+(.[0-9]{1,2})?$** - 这样就允许用户只写一位小数.下面我们该考虑数字中的逗号了,我们可以这样:**
^[0-9]{1,3}(,[0-9]{3})\*(.[0-9]{1,2})?$** - 1到3个数字,后面跟着任意个 逗号+3个数字,逗号成为可选,而不是必须:**
^([0-9]+|[0-9]{1,3}(,[0-9]{3})\*)(.[0-9]{1,2})?$** - 备注:这就是最终结果了,别忘了”+”可以用”*”替代如果你觉得空字符串也可以接受的话(奇怪,为什么?)最后,别忘了在用函数时去掉去掉那个反斜杠,一般的错误都在这里
- 有四种钱的表示形式我们可以接受:”10000.00” 和 “10,000.00”, 和没有 “分” 的 “10000” 和 “10,000”:**
- xml文件:**
^([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L]$** - 中文字符的正则表达式:**
[\u4e00-\u9fa5]** - 双字节字符:**
[^\x00-\xff](包括汉字在内,可以用来计算字符串的长度(一个双字节字符长度计2,ASCII字符计1))** - 空白行的正则表达式:**
\n\s\*\r(可以用来删除空白行)** - HTML标记的正则表达式:**
<(\S\*?)[^>]\*>.\*?|<.\*? />( 首尾空白字符的正则表达式:^\s\*|\s\*$或(^\s\*)|(\s\*$) (可以用来删除行首行尾的空白字符(包括空格、制表符、换页符等等),非常有用的表达式)** - 腾讯QQ号:**
[1-9][0-9]{4,}(腾讯QQ号从10000开始)** - 中国邮政编码:**
[1-9]\d{5}(?!\d)(中国邮政编码为6位数字)** - IPv4地址:**
((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3}**
该常用正则表达式内容来源:点击访问




